لماذا تفشل نماذج الذكاء الاصطناعي التوليدي في حل المسائل الرياضية؟

لقد أحدثت النماذج اللغوية الكبيرة تحولًا جذريًا في مجال الذكاء الاصطناعي، إذ ساهمت في تطوير تقنيات جديدة أصبحت جزءًا لا يتجزأ من حياتنا اليومية.
فقد أذهلتنا هذه النماذج بقدرتها على توليد نصوص إبداعية، مثل الشعر، وتلخيص الكتب، وتبسيط المعلومات المعقدة، والإجابة على استفسارات متنوعة بطلاقة مقاربة لطلاقة الإنسان، كما في حالة روبوتات الدردشة التي تستند في عملها إلى هذه النماذج، مثل: ChatGPT، وGemini.
ومع ذلك، تعاني نماذج الذكاء الاصطناعي التوليدي المتقدمة صعوبات في حل المسائل الرياضية، فعلى سبيل المثال: لا يستطيع نموذج (Claude) من شركة (Anthropic) حل المسائل الكلامية، ويفشل نموذج (Gemini) من جوجل في فهم المعادلات التربيعية، ويواجه نموذج (Llama) من ميتا في صعوبة في إجراء عمليات الجمع الأساسية.
ولكن كيف يمكن للنموذج الذي يفهم المعاني الخفية للكلمات ويؤلف الشعر أن يعجز عن حل مسائل حسابية يتقنها تلاميذ المدارس الابتدائية؟ دعونا نستكشف الأسباب الكامنة وراء هذا الفشل.
لماذا تفشل نماذج الذكاء الاصطناعي التوليدي في الرياضيات؟
لكي نفهم سبب فشل نماذج الذكاء الاصطناعي التوليدي في الرياضيات، نحتاج أولًا إلى فهم كيفية عمل هذه النماذج لمعالجة اللغة الطبيعية والتنبؤ بها، تُوصف النماذج اللغوية الكبيرة بأنها (ببغاوات عشوائية)، وهو مصطلح صاغته (إميلي بندر)، الباحثة في جامعة واشنطن، لوصف آلية عملها، فمثل الببغاء الذي يقلد الأصوات دون فهم معناها، تقوم هذه النماذج بتجميع الكلمات والجمل بناءً على الأنماط التي تعلمتها من كميات ضخمة من البيانات النصية، دون أن يكون لديها فهم عميق للمعنى الكامن وراء تلك الأنماط.
لذلك يكمن أحد الأسباب الرئيسية في فشل هذه النماذج في حل المسائل الرئيسية في الطريقة التي تعالج بها اللغة والرموز، وهي طريقة (التجزئة) Tokenization، وهي عملية تقسيم النص إلى وحدات أصغر تُسمى (tokens)، ويمكن أن تكون هذه الوحدات كلمات، أو أجزاء من كلمات (مثل الجذور اللغوية)، أو رموز، أو حتى أحرف فردية، اعتمادًا على الغرض من التحليل.
وتُعدّ هذه العملية خطوة أساسية في تدريب هذه النماذج، ومع أنها تساعد النموذج على فهم المعنى العام للنص، لكنها تؤدي إلى فقدان بعض المعلومات الدقيقة، خاصة فيما يتعلق بالأرقام والعلاقات العددية. فعلى سبيل المثال، قد يعامل النموذج الرقم (380) كرمز واحد، لكنه قد يمثل الرقم (381) كزوج من الأرقام (38 و 1)، مما يؤثر في قدرته على إجراء العمليات الحسابية بدقة.
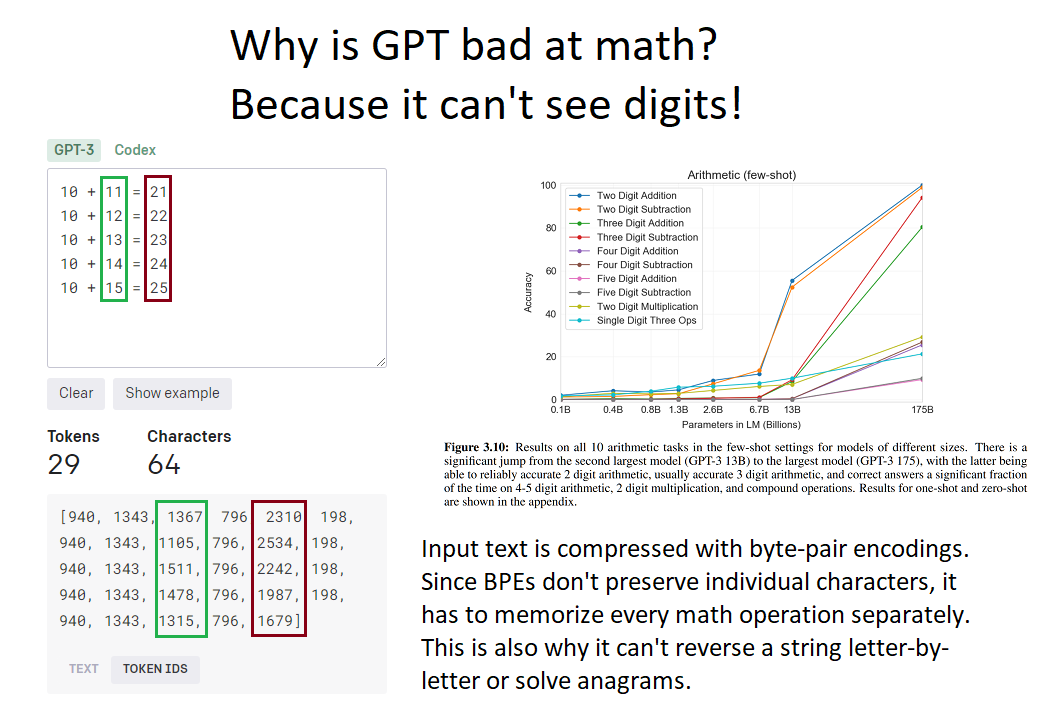{kind=link}
بالإضافة إلى ذلك، تعتمد نماذج الذكاء الاصطناعي التوليدي على الإحصاء والاحتمالات للتنبؤ بالكلمة التالية في الجملة، فهي تحلل كميات ضخمة من البيانات النصية لتحديد الأنماط الإحصائية بين الكلمات والعبارات، وبناءً على هذه الأنماط، تتوقع النماذج الكلمة التالية في الجملة.
فعلى سبيل المثال، إذا تعلم النموذج أن كلمة (القط) غالبًا ما تتبعها كلمة (يلعب)، فمن المحتمل أن يختار كلمة (يلعب) عندما يواجه كلمة (القط) في سياق جديد. ومع ذلك، يجعل هذا النهج الإحصائي النماذج عرضة للأخطاء، خاصة عندما تواجه سياقات غير مألوفة أو عندما تُطلب منها إجراء استدلالات منطقية.
ويؤدي ذلك إلى فشل هذه النماذج في فهم القواعد الرياضية الأساسية، فعلى سبيل المثال، عند الطلب من ChatGPT ضرب عددين كبيرين مثل (57897 × 12832)، سيعتمد ChatGPT على الأنماط التي تعلمها من من البيانات التدريبية، وسيلاحظ أن حاصل ضرب 7 و 2 يساوي 14، لذلك يستنتج أن حاصل ضرب عددين ينتهي أحدهما بالرقم (7)، والآخر بالرقم (2) سينتهي بالرقم (4).
ويؤدي هذا التبسيط الزائد إلى خطأ كبير، إذ إن ChatGPT يتجاهل باقي الأرقام وحسابات الضرب المعقدة الأخرى، وقد كانت النتيجة التي قدمها (ChatGPT) هي (742,021,104)، في حين الإجابة الصحيحة هي (742,934,304).
وقد أظهرت دراسة أجراها يونتيان دينج، الأستاذ المساعد في جامعة واترلو والمتخصص في الذكاء الاصطناعي، أن نموذج (GPT-4o) المتقدم يواجه صعوبات في إجراء عمليات ضرب للأعداد الكبيرة التي تتكون من أكثر من أربعة أرقام، فعلى سبيل المثال، عجز النموذج عن حساب ضرب عددين مثل 3459 و 5284 بدقة.
وقال يونتيان دينج: “يواجه نموذج GPT-4o صعوبات كبيرة في إجراء عمليات الضرب المتعددة الأرقام، إذ يحقق النموذج دقة أقل من 30% في المسائل التي تتضمن أعدادًا مكونة من أربعة أرقام أو أكثر”.
وأوضح دينج أن الضرب المتعدد الأرقام يشكل تحديًا للنماذج اللغوية الكبيرة لأن الخطأ في أي خطوة وسيطة يمكن أن يتضاعف، مما يؤدي إلى نتائج نهائية غير صحيحة.
ولكن إلى متى ستظل الرياضيات تمثل مشكلة بالنسبة لهذه النماذج؟
لقد أثار سؤال قدرة النماذج اللغوية الكبيرة مثل ChatGPT على إتقان العمليات الحسابية جدلًا واسعًا خلال المدة الماضية خاصة مع اعتماد الطلاب عليها، فهل ستظل هذه النماذج محدودة في أدائها الرياضي، أم أنها ستتطور مع الوقت؟
أظهرت دراسة حديثة أجراها يونتيان دينج وزملاؤه في جامعة واترلو، إمكانية تطوير هذه النماذج في مجال الرياضيات، ففي حين واجه نموذج GPT-4o صعوبة في إجراء عمليات الضرب المعقدة، فقد حقق نموذج (o1) الجديد – الذي أطلقته شركة (OpenAI) خلال شهر سبتمبر الماضي، والمُصمم لقضاء المزيد من الوقت في التفكير بطريقة أقرب إلى التفكير البشري قبل الرد على استفسارات المستخدم – نتائج واعدة.
إذ تمكن نموذج (o1) من حل مسائل ضرب تتكون من تسعة أرقام في تسعة أرقام بشكل صحيح في نحو نصف الوقت.
وقال دينج: “قد يتبع النموذج طرقًا مختلفة لحل المسائل مقارنة بالبشر، وهذا يجعلنا فضوليين بشأن النهج الداخلي للنموذج وكيف يختلف عن الاستدلال البشري”.
ويُعبر دينج عن تفاؤل كبير حيال مستقبل هذه النماذج، مؤكدًا أن بعض المسائل الرياضية، وخاصة مسائل الضرب التي تعتمد على خوارزميات واضحة، ستصبح قابلة للحل باستخدام نماذج مشابهة لـ ChatGPT. ويشير إلى التطور الملحوظ من نموذج (GPT-4o) إلى النموذج الأحدث (o1) كدليل على أن قدرات الاستدلال المنطقي لهذه النماذج تتطور بصورة مستمرة.
ويشير هذا التقدم إلى أن النماذج اللغوية الكبيرة قادرة على التعلم والتطور بسرعة، مما يفتح الباب أمام إمكانيات جديدة في مجالات مثل التعليم والبحث العلمي. ومع ذلك، لا يزال هناك الكثير من العمل الذي يجب القيام به قبل أن تتمكن هذه النماذج من منافسة البشر والآلات المتخصصة في جميع المجالات الرياضية.
تم نسخ الرابط